近期在读一本名为《Expert Indexing in Oracle Database 11g》的书,个人觉得写的很不错,收获颇多。在这里就把一些关于CBO 通过INDEX 扫描数据的相关知识稍作整理,算是读书笔记。
其中,在读到第7章,Tuning Index Usage时,提到常见的通过索引访问数据的方式有下述几种:
Index Unique Scan;
Index Range Scan;
Index Skip Scan;
Index Full Scan;
Index Fast Full Scan;
这里,首先说Index Unique Scan。
CBO【Cost Based Optimizer】通常在什么场景下会选择通过Index Unique Scan的方式来访问数据呢?
1 必须是通过唯一索引【UNIQUE】来访问数据;
2 通过唯一索引来访问数据时,每次返回的记录数必须是1条;
3 WHERE从句中必须要用等值【=】条件来过滤数据;
我个人目前的理解是,必须同时满足上述3个条件,CBO才会选择通过Index Unique Scan的路径来访问数据。
下面给出验证:
1 操作系统版本和数据库版本:
操作系统:
[oracle@oracle11g ~]$ uname -rm 2.6.18-194.el5 x86_64 [oracle@oracle11g ~]$
数据库:
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for Linux: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production SQL>
2 测试表、表结构、表数据如下:
SQL> conn hr/hr
Connected.
SQL> desc departments;
Name Null? Type
----------------------------------------- -------- ----------------------------
DEPARTMENT_ID NOT NULL NUMBER(4)
DEPARTMENT_NAME NOT NULL VARCHAR2(30)
MANAGER_ID NUMBER(6)
LOCATION_ID NUMBER(4)
SQL> select * from departments;
DEPARTMENT_ID DEPARTMENT_NAME MANAGER_ID LOCATION_ID
------------- ------------------------------ ---------- -----------
10 Administration 200 1700
20 Marketing 201 1800
30 Purchasing 114 1700
40 Human Resources 203 2400
50 Shipping 121 1500
60 IT 103 1400
70 Public Relations 204 2700
80 Sales 145 2500
90 Executive 100 1700
100 Finance 108 1700
110 Accounting 205 1700
DEPARTMENT_ID DEPARTMENT_NAME MANAGER_ID LOCATION_ID
------------- ------------------------------ ---------- -----------
120 Treasury 1700
130 Corporate Tax 1700
140 Control And Credit 1700
150 Shareholder Services 1700
160 Benefits 1700
170 Manufacturing 1700
180 Construction 1700
190 Contracting 1700
200 Operations 1700
210 IT Support 1700
220 NOC 1700
DEPARTMENT_ID DEPARTMENT_NAME MANAGER_ID LOCATION_ID
------------- ------------------------------ ---------- -----------
230 IT Helpdesk 1700
240 Government Sales 1700
250 Retail Sales 1700
260 Recruiting 1700
270 Payroll 1700
27 rows selected.
SQL>
3 该表上的索引信息如下:
SQL> select index_name,index_type,table_name,uniqueness from user_indexes where table_name='DEPARTMENTS'; INDEX_NAME INDEX_TYPE TABLE_NAME UNIQUENES ------------------------------ --------------------------- ------------------------------ --------- DEPT_ID_PK NORMAL DEPARTMENTS UNIQUE DEPT_LOCATION_IX NORMAL DEPARTMENTS NONUNIQUE SQL> select * from user_ind_columns where table_name='DEPARTMENTS'; INDEX_NAME TABLE_NAME COLUMN_NAME COLUMN_POSITION COLUMN_LENGTH CHAR_LENGTH DESC ------------------------------ ------------------------------ --------------- --------------- ------------- ----------- ---- DEPT_ID_PK DEPARTMENTS DEPARTMENT_ID 1 22 0 ASC DEPT_LOCATION_IX DEPARTMENTS LOCATION_ID 1 22 0 ASC SQL>
从上看到departments表有2个索引,其中在DEPARTMENT_ID字段上的索引DEPT_ID_PK 为主键索引,是个UNIQUE类型的索引。而LOCATION_ID 字段上的DEPT_LOCATION_IX则为非唯一【NONUNIQUE】索引。
4 通过该表上的主键字段department_id来定位数据:
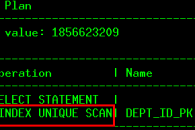
SQL> set autotrace trace
SQL> select department_id from departments where department_id=270;
Execution Plan
----------------------------------------------------------
Plan hash value: 1856623209
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 0 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| DEPT_ID_PK | 1 | 4 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("DEPARTMENT_ID"=270)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1 consistent gets
0 physical reads
0 redo size
532 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
从上述执行计划里看到,CBO选择了Index Unique Scan,因为department_id字段上有一个DEPT_ID_PK 的UNIQUE类型的索引,且上述SQL满足Index Unique Scan的条件。
而如果WHERE条件换成department_id>=270时,则CBO选择了Index Range Scan的访问路径,因为该WHERE条件是>=而非等值匹配。CBO认为返回的记录数可能不止1条,即使实际情况下满足条件的记录数确实是1条,所以选择了Index Range Scan。
SQL> select department_id from departments where department_id>=270;
Execution Plan
----------------------------------------------------------
Plan hash value: 4271874676
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| DEPT_ID_PK | 1 | 4 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("DEPARTMENT_ID">=270)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1 consistent gets
0 physical reads
0 redo size
532 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
5 通过该表上的location_id字段来定位数据的场景:
SQL> select location_id from departments where location_id=2700;
Execution Plan
----------------------------------------------------------
Plan hash value: 2790119751
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| DEPT_LOCATION_IX | 1 | 3 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("LOCATION_ID"=2700)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1 consistent gets
0 physical reads
0 redo size
529 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select location_id from departments where location_id=1700;
21 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2790119751
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 21 | 63 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| DEPT_LOCATION_IX | 21 | 63 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("LOCATION_ID"=1700)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
901 bytes sent via SQL*Net to client
535 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
21 rows processed
SQL>
从上述执行计划看到,通过LOCATION_ID 字段上的DEPT_LOCATION_IX来定位数据时,不管是通过location_id=2700还是location_id=1400或者location_id=1700,结果都是走INDEX RANGE SCAN。因为DEPT_LOCATION_IX不是唯一索引,即使location_id=2700或者location_id=1400条件能确保返回的记录数只有1条,CBO也不会选择Index Unique Scan。
6 通过唯一索引、非唯一索引来定位数据的场景:
非唯一索引的情况:
SQL> create table all_t as select object_id,object_name from all_objects;
Table created.
SQL> desc all_t;
Name Null? Type
----------------------------------------- -------- ----------------------------
OBJECT_ID NOT NULL NUMBER
OBJECT_NAME NOT NULL VARCHAR2(30)
SQL> select table_name,index_name,index_type,uniqueness from user_indexes where table_name='ALL_T';
no rows selected
SQL> create index idx_all_t on all_t(object_id);
Index created.
SQL> select table_name,index_name,index_type,uniqueness from user_indexes where table_name='ALL_T';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENES
------------------------------ ------------------------------ --------------------------- ---------
ALL_T IDX_ALL_T NORMAL NONUNIQUE
SQL> exec dbms_stats.gather_table_stats(user,'all_t',cascade=>true);
PL/SQL procedure successfully completed.
SQL> set autotrace trace
SQL> select * from all_t where object_id=30000;
Execution Plan
----------------------------------------------------------
Plan hash value: 2459308467
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 31 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ALL_T | 1 | 31 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ALL_T | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=30000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
627 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
唯一索引的情况:
SQL> drop index idx_all_t ;
Index dropped.
SQL> create unique index idx_all_t on all_t(object_id);
Index created.
SQL> select table_name,index_name,index_type,uniqueness from user_indexes where table_name='ALL_T';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENES
------------------------------ ------------------------------ --------------------------- ---------
ALL_T IDX_ALL_T NORMAL UNIQUE
SQL> set autotrace trace
SQL> exec dbms_stats.gather_table_stats(user,'all_t',cascade=>true);
PL/SQL procedure successfully completed.
SQL> select * from all_t where object_id=30000;
Execution Plan
----------------------------------------------------------
Plan hash value: 3932529197
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 31 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ALL_T | 1 | 31 | 2 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | IDX_ALL_T | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=30000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
491 bytes sent via SQL*Net to client
512 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
从上可以看到,虽然测试表all_t上的字段object_id字段虽然的确可以确保唯一,但是在第一种情况下,索引IDX_ALL_T为非唯一索引的时候,CBO毅然选择了INDEX RANGE SCAN,而第二种情况下,却是Index Unique Scan。
也就是说,即使可以确保表中某个字段是唯一的,如果该字段上的索引不是唯一的,那么CBO选择的将是通过INDEX RANGE SCAN的路径来访问数据。想要表达的是,真实场景下这种情况的确会存在,因为有些系统是通过应用程序来保证表中的字段唯一,而并没有在表上对应的字段上通过创建唯一约束或者是唯一索引来保证数据的唯一性。那么,这样的话,将会导致CBO在选择执行计划的情况下,有可能会出现偏差。所以,对于这种情况下,即使应用程序可以保证数据的唯一性,最好还是在表上创建一个唯一索引比较稳妥。
最后,留一个小疑问给所有的看到这篇文章的朋友,对于第6种情况,是不是第二种场景下的Index Unique Scan的效率要高于第一种场景下的INDEX RANGE SCAN?因为,从执行计划来看的话,一致性读的次数分别为3和4。


.png)

.png)































.png)
















