一 首先,接到帮助请求
二 分析错误和定位问题
对于不熟悉Oracle错误的同学,可以参考metalink(Oracle官方技术支持网站)官方文档(What is an ORA-600 Internal Error? (Doc ID 146580.1))的解释:
什么是ORA-600?
*ORA-600 errors are raised from the kernel code of the Oracle RDBMS software when an internal inconsistency is detected or an unexpected condition is met. This situation is not necessarily a bug as it might be caused by problems with the Operating System, lack of resources, hardware failures, etc.
With the ORA-600 error comes a list of arguments in square brackets. The first of these arguments tells us from where in the code the error was caught and thus is the key information in identifying the problem. This argument is either a number or a character string. The remaining arguments are used to supply further information (e.g. values of internal variables etc).
Whenever an ORA-600 error is raised a trace file is generated and an entry written to the alert.log with details of the trace file location. Starting with Oracle Database 11g Release 1, the diagnosability infrastructure was introduced which places the trace and core files into a location controlled by the DIAGNOSTIC_DEST initialization parameter when an incident, such as an ORA-600 is created. For earlier versions, the trace file will be written to either USER_DUMP_DEST (if the error was caught in a user process) or BACKGROUND_DUMP_DEST (if the error was caught in a background process like PMON or SMON). The trace file contains vital information about what led to the error condition.*
所以,我们从错误信息参数中,可以猜测出,ORA-00600: internal error code, arguments: [kclchkblk_4]应该是跟数据块错误有关的可能性很大。再结合这个案例,网友提供的信息说存储控制器故障,猜测多半情况下,数据库在运行(数据库进程通过内存空间,频繁和存储设备读写数据)的过程中,存储控制器一旦故障,多数情况下会导致内存中的脏数据(被修改过的数据)无法写入数据库,或者数据库检查点信息无法同步到控制文件、日志文件、数据文件中。那么数据库必死无疑,无法再继续工作下去了,当我们下次手工启库、或者数据库自动重启的过程中,数据库在open阶段,如果数据库无法完成一致性校验或者Instance Recovery实例恢复,那么数据库就无法Open,不能对业务系统提供服务了。
那么,本案例中,这个ORA-00600: internal error code, arguments: [kclchkblk_4]究竟表示什么意思呢?后面的几个参数又表示什么呢?我想,如果我们能把这几个参数搞清楚的话,那么这个问题也许就有眉目了。
于是,从metalink上找到跟该错误有关的几篇文章:
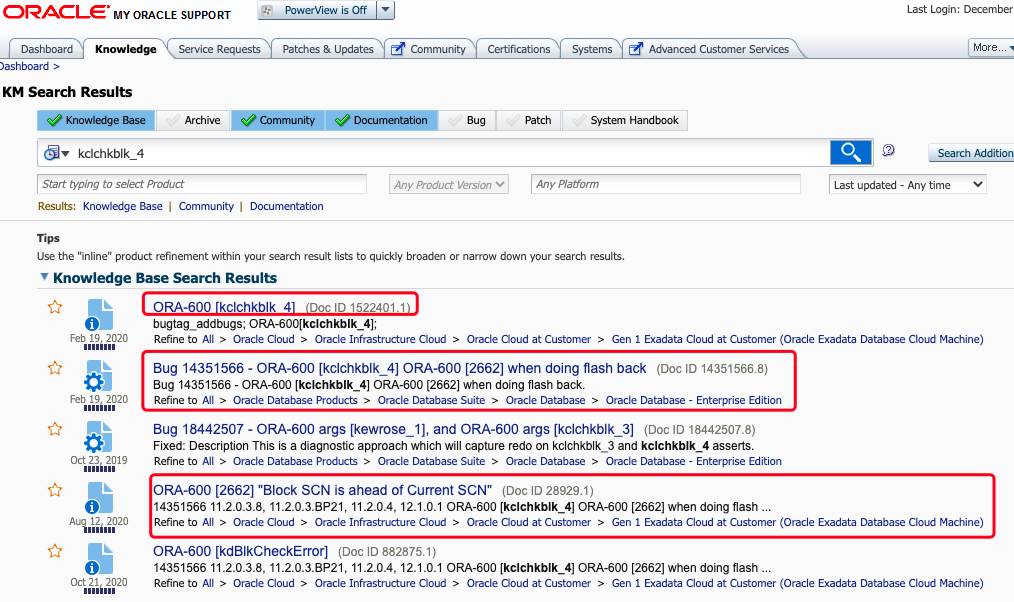
1 ORA-600 [kclchkblk_4] (Doc ID 1522401.1)
ORA-600 [kclchkblk_4] (Doc ID 1522401.1)
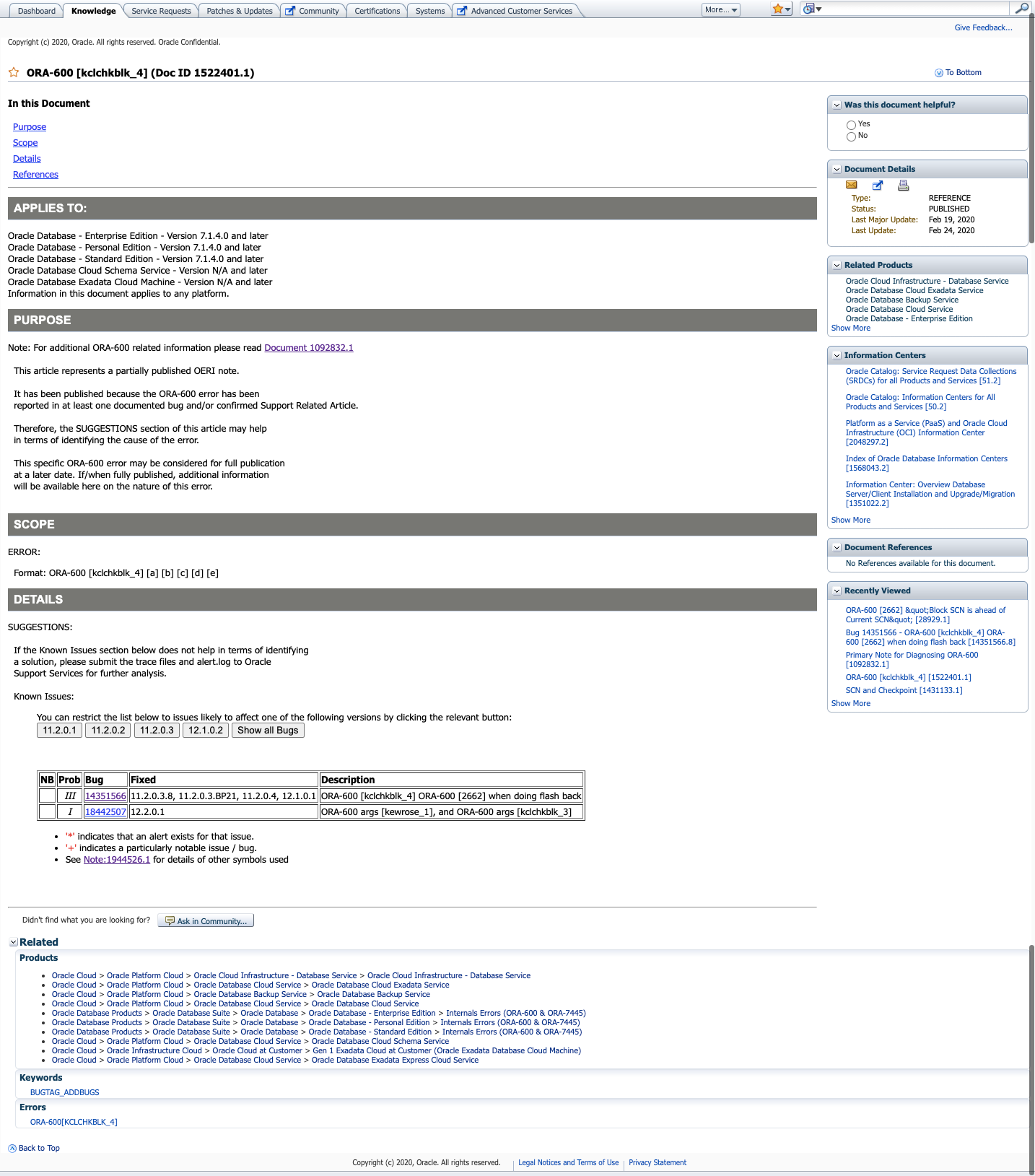
2 Bug 14351566 – ORA-600 [kclchkblk_4] ORA-600 [2662] when doing flash back (Doc ID 14351566.8)
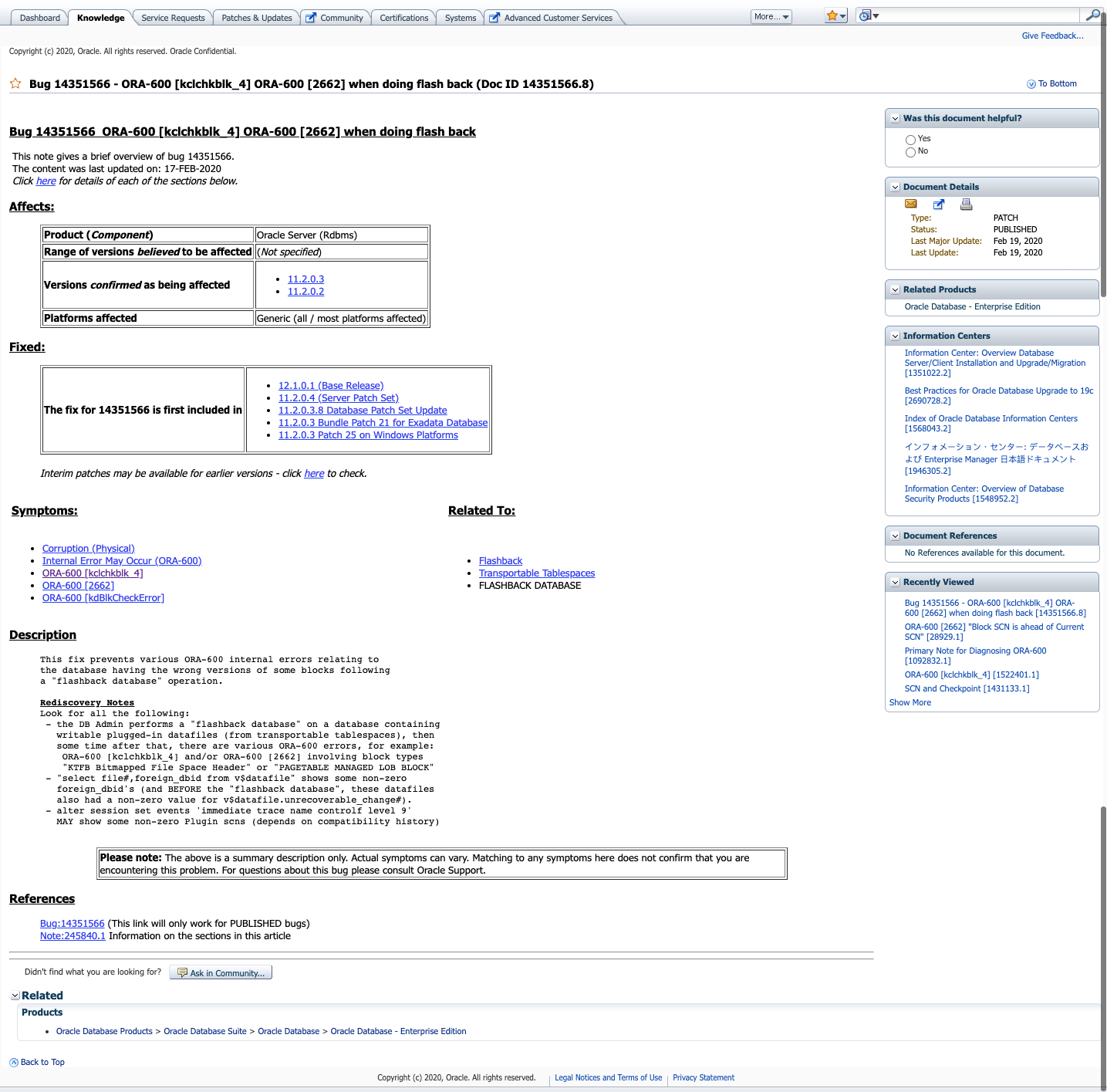
该文档描述的是数据库多次执行flashback之后,导致的bug。我们该故障场景中,数据库并没有执行flashback的操作,排除。
3 ORA-600 [2662] “Block SCN is ahead of Current SCN” (Doc ID 28929.1)

不过,从该指导文档中可以获取到对此案例有用的指导信息。
① 该错误比较常见,通常由于存储故障、或者服务器异常掉电,数据库abort关闭等,导致的数据块里记录的SCN与数据库当前SCN不一致导致的。解决问题的常规办法就是通过redo log恢复数据,如果依然不奏效的话,可能需要通过非常规手段来修改数据库的SCN,使之一致,进而避免该错误发生。
这里,我在一套测试环境上模拟了该错误,并且手工修复了该错误:
Sat Dec 19 08:55:28 2020
SMON: enabling cache recovery
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_8251.trc (incident=28953):
ORA-00600: internal error code, arguments: [2662], [0], [112587826], [0], [112587881], [4194432], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_28953/orcl_ora_8251_i28953.trc
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_8251.trc:
ORA-00600: internal error code, arguments: [2662], [0], [112587826], [0], [112587881], [4194432], [], [], [], [], [], []
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_8251.trc:
ORA-00600: internal error code, arguments: [2662], [0], [112587826], [0], [112587881], [4194432], [], [], [], [], [], []
Error 600 happened during db open, shutting down database
USER (ospid: 8251): terminating the instance due to error 600
Instance terminated by USER, pid = 8251
ORA-1092 signalled during: alter database open resetlogs...
opiodr aborting process unknown ospid (8251) as a result of ORA-1092
Sat Dec 19 08:55:33 2020
当然,这是另外一个case,我们暂且不去聚焦这个ORA-600 26662的错误如果解决。如果大家感兴趣且有需求的话,我可以另外录制一个视频去讲解它。
②从该文档中,倒是给出了有意义的错误参数:
ARGUMENTS:
Arg [a] Current SCN WRAP
Arg [b] Current SCN BASE
Arg [c] dependent SCN WRAP
Arg [d] dependent SCN BASE
Arg [e] Where present this is the DBA where the dependent SCN came from.
可以看出,这些错误参数,跟前面提到的错误参数格式非常一致:
RROR:
Format: ORA-600 [kclchkblk_4] [a] [b] [c] [d] [e]
但是,Oracle官方并没有给出这里的几个参数表示的具体意义。
那么,进一步猜测,我们这个故障的错误是不是也可以借鉴于该文档中给出的suggestion来尝试恢复呢?
③ 官方给出的几个suggestion
SUGGESTIONS:
There are different situations where ORA-600 [2662] can be raised.
It can be raised on startup or during database operation.
If not using Parallel Server, check that 2 instances have not mounted
the same database.
Check for SMON traces and have the alert.log and trace files ready
to send to support.
Check the SCN difference [argument d]-[argument b].
If the SCNs in the error are very close, then try to shutdown and startup
the instance several times.
In some situations, the SCN increment during startup may permit the
database to open. Keep track of the number of times you attempted a
startup.
到这里,有了一个可以尝试的解决问题的思路了,如果ORA-600 [kclchkblk_4] [a] [b] [c] [d] [e]这里的几个参数也表示某种与SCN有关的信息的话,那么,是不是可以根据该建议尝试恢复呢?
三 解决问题
1 start instance,确认错误参数是否推进
Tue Dec 08 15:04:02 2020
Thread 1 advanced to log sequence 9 (thread open)
Thread 1 opened at log sequence 9
Current log# 1 seq# 9 mem# 0: +DATA/jhzmpr/onlinelog/group_1.262.1045198071
Current log# 1 seq# 9 mem# 1: +DATA/jhzmpr/onlinelog/group_1.263.1045198071
Successful open of redo thread 1
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Tue Dec 08 15:04:02 2020
SMON: enabling cache recovery
SUCCESS: diskgroup ARCH was mounted
Archived Log entry 1831 added for thread 1 sequence 8 ID 0xddd7c8e4 dest 1:
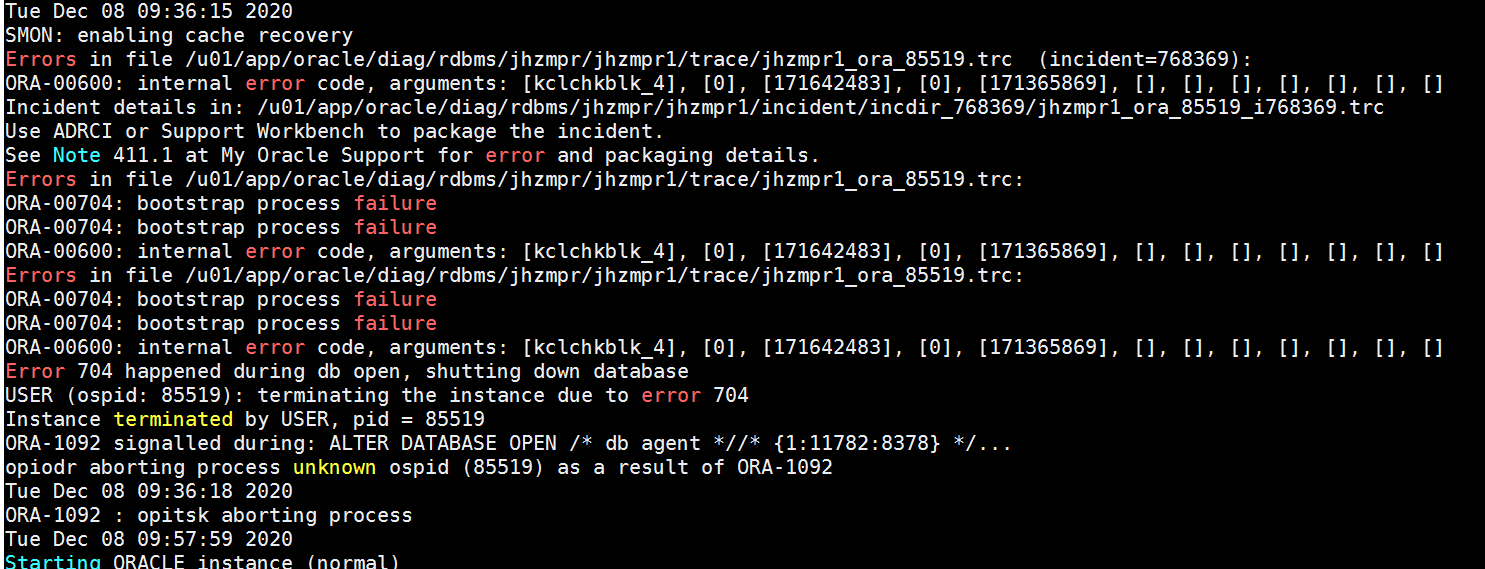
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_17070.trc (incident=800345):
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171385871], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/incident/incdir_800345/jhzmpr1_ora_17070_i800345.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
NOTE: dependency between database jhzmpr and diskgroup resource ora.ARCH.dg is established
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_17070.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171385871], [], [], [], [], [], [], []
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_17070.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171385871], [], [], [], [], [], [], []
Error 704 happened during db open, shutting down database
USER (ospid: 17070): terminating the instance due to error 704
Instance terminated by USER, pid = 17070
ORA-1092 signalled during: alter database open...
opiodr aborting process unknown ospid (17070) as a result of ORA-1092
Tue Dec 08 15:04:05 2020
ORA-1092 : opitsk aborting process
果不其然,argument d比上次推进了:从之前的171365869推进到171385871。同时,argument b保持不变,其它错误信息也保持一致。
2 继续上述操作
[root@jhzmpr01 ~]# srvctl start db -d jhzmpr
PRCR-1079 : Failed to start resource ora.jhzmpr.db
CRS-5017: The resource action "ora.jhzmpr.db start" encountered the following error:
ORA-01092: ORACLE instance terminated. Disconnection forced
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171405876], [], [], [], [], [], [], []
Process ID: 21207
Session ID: 3175 Serial number: 3
. For details refer to "(:CLSN00107:)" in "/u01/app/11.2.0/grid/log/jhzmpr01/agent/crsd/oraagent_oracle//oraagent_oracle.log".
CRS-5017: The resource action "ora.jhzmpr.db start" encountered the following error:
ORA-01092: ORACLE instance terminated. Disconnection forced
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171405882], [], [], [], [], [], [], []
Process ID: 43944
Session ID: 3175 Serial number: 3
. For details refer to "(:CLSN00107:)" in "/u01/app/11.2.0/grid/log/jhzmpr02/agent/crsd/oraagent_oracle//oraagent_oracle.log".
CRS-2674: Start of 'ora.jhzmpr.db' on 'jhzmpr01' failed
CRS-2674: Start of 'ora.jhzmpr.db' on 'jhzmpr02' failed
CRS-2632: There are no more servers to try to place resource 'ora.jhzmpr.db' on that would satisfy its placement policy
[root@jhzmpr01 ~]#
3 直至错误参数一致
Tue Dec 08 15:44:31 2020
SMON: enabling cache recovery
SUCCESS: diskgroup ARCH was mounted
Archived Log entry 1846 added for thread 1 sequence 22 ID 0xddd7c8e4 dest 1:
NOTE: dependency between database jhzmpr and diskgroup resource ora.ARCH.dg is established
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_54315.trc (incident=1248369):
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171679465], [0], [171665974], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/incident/incdir_1248369/jhzmpr1_ora_54315_i1248369.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_54315.trc:
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171679465], [0], [171665974], [], [], [], [], [], [], []
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_54315.trc:
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171679465], [0], [171665974], [], [], [], [], [], [], []
Error 600 happened during db open, shutting down database
USER (ospid: 54315): terminating the instance due to error 600
Instance terminated by USER, pid = 54315
ORA-1092 signalled during: ALTER DATABASE OPEN /* db agent *//* {1:11782:10822} */...
opiodr aborting process unknown ospid (54315) as a result of ORA-1092
Tue Dec 08 15:44:34 2020
ORA-1092 : opitsk aborting process
4 启动数据库
Tue Dec 08 15:46:51 2020
Starting ORACLE instance (normal)
...
...
tarted redo scan
SUCCESS: diskgroup FLASH was mounted
Completed redo scan
read 11 KB redo, 5 data blocks need recovery
Started redo application at
Thread 1: logseq 23, block 3
Recovery of Online Redo Log: Thread 1 Group 5 Seq 23 Reading mem 0
Mem# 0: +DATA/jhzmpr/onlinelog/group_5.273.1046776933
Mem# 1: +FLASH/jhzmpr/onlinelog/group_5.256.1046776933
Completed redo application of 0.01MB
Completed crash recovery at
Thread 1: logseq 23, block 25, scn 171685974
5 data blocks read, 5 data blocks written, 11 redo k-bytes read
ARCH: STARTING ARCH PROCESSES
SMON: enabling tx recovery
*********************************************************************
WARNING: The following temporary tablespaces contain no files.
This condition can occur when a backup controlfile has
been restored. It may be necessary to add files to these
tablespaces. That can be done using the SQL statement:
ALTER TABLESPACE <tablespace_name> ADD TEMPFILE
Alternatively, if these temporary tablespaces are no longer
needed, then they can be dropped.
Empty temporary tablespace: TEMP
*********************************************************************
Database Characterset is AL32UTF8
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_smon_57089.trc (incident=1280273):
ORA-00600: internal error code, arguments: [4194], [], [], [], [], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/incident/incdir_1280273/jhzmpr1_smon_57089_i1280273.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
5 至此,该错误已经消失了,数据库可以正常访问了。
但是,alert日志里抛出一个报警,让我们给数据库添加临时文件。为什么呢?这是因为,这位网友之前根据网上的一些帖子尝试对数据库删除临时文件,但是没能恢复数据库。这里,我们可以先不去理会临时文件的文件,可以让数据库使用SYSAUX那个表空间充当临时表空间,如果需要的话。
四 补充
1 SCN
①定义
System Change Number,数据库“内部时钟”,数据库中每时每刻都在发生改变,这些改变对应这一个具体的时间点儿,每个具体的时间点儿对应一个数字编号,这个编号就是SCN值。比如:2020年12月19日18时30分52秒,对应一个SCN号,35789713456。注意,不同时间点儿对应不同的SCN,数据库一旦启动运行,SCN就不停向前滚动。
② 作用
对于关系型数据库而言,用于事务的ACID控制和管理,以及数据库的备份和恢复的标准。
③位置
数据文件、控制文件、日志文件、数据文件头、数据块中都有记录。
④查看
SQL> select dbms_flashback.get_system_change_number scn from dual;
SCN
----------
112573590
SQL> select current_scn from v$database;
CURRENT_SCN
-----------
112573593
SQL> select file#,CHECKPOINT_CHANGE#,CHECKPOINT_TIME from v$datafile;
FILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME
---------- ------------------ -------------------
1 112563728 2020/12/19 15:38:19
2 112563728 2020/12/19 15:38:19
3 112563728 2020/12/19 15:38:19
4 112563728 2020/12/19 15:38:19
5 112563728 2020/12/19 15:38:19
6 112563728 2020/12/19 15:38:19
7 112563728 2020/12/19 15:38:19
7 rows selected.
SQL> select group#,FIRST_CHANGE#,FIRST_TIME from v$log;
GROUP# FIRST_CHANGE# FIRST_TIME
---------- ------------- -------------------
1 112563728 2020/12/19 15:38:19
2 112544279 2020/12/19 11:35:21
3 112551742 2020/12/19 12:37:46
SQL>
⑤结构和计数原理
占6个字节,48个二进制位数。前2个字节构成SCN_WRAP,最大值为2的16次方,65536。后4个字节构成SCN_BASE,最大值为2的32次方,4294967296。SCN总大小为2的48次方=281474976710656,281万亿个计数。
假定初始情况下,SCN_WRAP=0,SCN_BASE从1开始计数,当达到最大值4294967296时,就向前进一位,SCN_WRAP从0变为1,同时SCN_BASE从0重新开始计数,下一次达到最大值时,再向前进一位,SCN_WRAP再加1,SCN_BASE再次从0重新开始计数,以此循环往复。直至SCN用完耗尽为止。
SCN = (SCN_WRAP * 4294967296) + SCN_BASE
举个生活中的例子,类似于我们的计时秒表,当秒针从0跳到59时,分针从0变为1,同时秒针重新从0开始,直到到达下一个59秒,分针从1跳到2….

Oracle为什么要这么设计呢?这很好理解,例如,我们日常生活中会说3分28秒,很少有人直接说208秒,对不对? 就图一方便计数呗。
从Oracle12.2开始,SCN改为8个字节了,所以,其总大小变为2的63次方了。一个更大的数了。
2 Checkpoint
A checkpoint is the act of flushing modified, cached database blocks to disk. Normally, when you make a change to a block the modifications of that block are made to a memory copy of the block. When you commit the block, it is not written to the datafile but it is written to the REDO LOG, so we can “replay” a transaction in the event of an instance failure. Eventually, the system will checkpoint your modified blocks to the datafiles on disk.
-
-
When a redo log switch occurs.
-
Whenever the time set by the LOG_CHECKPOINT_TIMEOUT parameter is reached.
-
说一个简单的场景,假定我们要执行下述SQL,修改表里的一条记录:
update department set emp_name=’Huangwei’ where emp_name=’huangwei’;
update department set emp_name='Huangwei' where emp_name='huangwei';
数据库肯定不会直接到磁盘中去修改该数据,因为如果把数据读入到内存中,在内存中读写数据,比读写磁盘要快不止一个数量级。所以,
① 数据库先到内存中去找要修改的数据,如果内存中没有该数据的话,Oracle数据库的服务器进程把需要的数据从磁盘中读取到内存中;注意,Oracle不会只读这一条记录的数据,而是读取该记录所在的数据块,把整个数据块的内容全部读入内存。为了性能和效率,Oracle数据库肯定不会傻傻的一次只读一条记录的数据,最小IO单位是database block,其它关系型数据库也类似。
② 然后准备在内存中对该数据进行修改;真正修改之前,还要先做另外一件事儿:就是把这份数据放到一个undo回滚段中,用于确保事务的一致性读或者回滚等操作。接下来,给该SQL语句分配一个事务号,说白了就是一个SCN号。并开始执行真正的修改,同时,在redo log buffer里对该操作进行完整的记录(如:2020年12月19日19点40分,这个时间点儿其实就是这个个SCN,将‘huangwei’修改成了‘Huangwei’),为什么要记录这个呢?答案是便于恢复数据,这里就不再继续扩展。注意,该修改过的新数据(称为dirty buffer)并不一定马上写回到磁盘中;
③ 当我们执行commit时,这时,该修改过的新数据(称为dirty buffer)写回到磁盘中去了吗???
④ 也不一定,因为,此时只要保证redo log buffer里,记录的关于本条SQL修改的信息被LGWR后台进程写出到redo log file里,就算完成了。在不考虑数据库包含DATAGUARD备库的情况下,此时就可以立即返回commit成功,即告诉你,你的修改已经生效了。为什么呢?这就是Oracle的redo log file的作用,如果此时数据库出现instance crash的话,我的修改还在吗?在,Oracle可以利用写入到redo logfile里的内容,进行“redo”,或者叫“replay”。这也就是它为啥叫redo了。
⑤那问题来了?到底什么时候,我的这个修改被真正写回到磁盘中呢?答案,看情况。
比如:如果此时,数据库的database buffer cache不够用了,数据库会根据LRU算法把旧的脏数据写出到磁盘中;
或者:此时发生了redo logfile switch;
再:手工执行了 alter system checkpoint;等。
注意,把内存中的脏数据写出到数据文件是DBWR后台进程干的活儿;记录检查点信息到控制文件、同步到数据文件、日志文件中,则是CKPT后台进程的职责。
The checkpoint process updates the control file when a checkpoint is performed. Remember that a checkpoint operation writes all changed (dirty) blocks to disk. By recording this fact in the control file, Oracle knows what redo records need to be applied in the event of an instance failure. To recover from an instance failure, Oracle needs to apply all redo generated after the last checkpoint recorded in the control file.
-
Log switches cause checkpoints. Checkpoints do not cause log switches.
-
DBWR writes dirty blocks from the buffer cache to disk — that does not happen when you “commit” — LGWR is involved during a commit.
五 小结
1 解决该数据库故障并不难
只是需要不停的startup,shudown,再startup。难点在于去分析和定位该问题,找到一些相关的线索,并支撑和问题相关的错误信息。
2 如何规避该问题
如果这位网友的数据库,在故障发生之前,执行了合适的热备份+归档的话,遇到该故障的时候,可能就没有这么被动。
3 备份很重要
在遇到数据库故障或者错误的场景下,一定要尽可能的先对数据库进行备份,保留数据库故障现场,便于后续恢复不成功的情况下,可以多次重新尝试。另外,如果的确没有十足把握的话,不要轻易尝试对数据库执行各种恢复操作。总结该故障的过程中,发现系统报错时间:
Sun Dec 06 05:16:31 2020
Thread 1 advanced to log sequence 652 (LGWR switch)
Current log# 2 seq# 652 mem# 0: +DATA/jhzmpr/onlinelog/group_2.264.1045198071
Current log# 2 seq# 652 mem# 1: +DATA/jhzmpr/onlinelog/group_2.265.1045198073
Sun Dec 06 05:16:33 2020
Archived Log entry 1816 added for thread 1 sequence 651 ID 0xdd0af974 dest 1:
Sun Dec 06 05:45:39 2020
WARNING: Write Failed. group:2 disk:2 AU:54678 offset:49152 size:8192
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_dbwb_7076.trc:
ORA-15080: synchronous I/O operation to a disk failed
ORA-27061: waiting for async I/Os failed
Linux-x86_64 Error: 5: Input/output error
Additional information: -1
Additional information: 8192
WARNING: failed to write mirror side 1 of virtual extent 7778 logical extent 0 of file 315 in group 2 on disk 2 allocation unit 54678
KCF: read, write or open error, block=0xf3106 online=1
file=10 '+DATA/jhzmpr/datafile/aoi.315.1057790147'
error=15081 txt: ''
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_dbwb_7076.trc:
Sun Dec 06 05:45:39 2020
WARNING: Read Failed. group:2 disk:0 AU:340 offset:49152 size:16384
WARNING: failed to read mirror side 1 of virtual extent 4 logical extent 0 of file 261 in group [2.4004072768] from disk DATA_0000 allocation unit 340 reason error; if possible, will try another mirror side
Sun Dec 06 05:45:39 2020
...
...
Sun Dec 06 05:45:46 2020
License high water mark = 102
Termination issued to instance processes. Waiting for the processes to exit
Sun Dec 06 05:46:00 2020
Instance termination failed to kill one or more processes
Instance terminated by CKPT, pid = 7080
Sun Dec 06 05:46:00 2020
第一次手工尝试恢复故障:
Sun Dec 06 14:28:32 2020
Starting ORACLE instance (normal)
...
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_6706.trc:
ORA-00742: Log read detects lost write in thread %d sequence %d block %d
ORA-00312: online log 2 thread 1: '+DATA/jhzmpr/onlinelog/group_2.265.1045198073'
ORA-00312: online log 2 thread 1: '+DATA/jhzmpr/onlinelog/group_2.264.1045198071'
ORA-742 signalled during: ALTER DATABASE OPEN /* db agent *//* {1:11782:2} */...
Sun Dec 06 14:28:57 2020
Shutting down instance (abort)
第二次
Sun Dec 06 23:37:03 2020
Starting ORACLE instance (normal)
...
Mon Dec 07 00:27:06 2020
alter database clear unarchived logfile group 2
ORA-1624 signalled during: alter database clear unarchived logfile group 2...
Mon Dec 07 00:28:08 2020
ALTER DATABASE RECOVER database using backup controlfile until cancel
Media Recovery Start
started logmerger process
Mon Dec 07 00:28:08 2020
...
Mon Dec 07 00:29:27 2020
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_pr00_43688.trc:
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '+DATA/jhzmpr/datafile/system.256.1045198003'
ORA-1547 signalled during: ALTER DATABASE RECOVER CANCEL ...
ALTER DATABASE RECOVER CANCEL
ORA-1112 signalled during: ALTER DATABASE RECOVER CANCEL ...
Mon Dec 07 00:29:41 2020
alter database open resetlogs
ORA-1194 signalled during: alter database open resetlogs...
Mon Dec 07 00:30:17 2020
ALTER DATABASE RECOVER database using backup controlfile until cancel allow 1 corruption
Media Recovery Start
Serial Media Recovery started
...
Mon Dec 07 22:28:46 2020
SMON: enabling cache recovery
Instance recovery: looking for dead threads
Instance recovery: lock domain invalid but no dead threads
Errors in file /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/trace/jhzmpr1_ora_39995.trc (incident=576369):
ORA-00600: internal error code, arguments: [kclchkblk_4], [0], [171642483], [0], [171225822], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/jhzmpr/jhzmpr1/incident/incdir_576369/jhzmpr1_ora_39995_i576369.trc
Use ADRCI or Support Workbench to package the incident.
4 祸不单行,福无双降,顺手帮忙
这个库处理好之后,那哥们儿出于对我的信任,又请我帮忙处理同样跑在该存储设备上另外几个同样没能幸免于难的数据库故障。那些使用该存储设备作为数据库存储的好几个数据库都挂了,
5 参考链接
https://topic.alibabacloud.com/a/ora-00600-kclchkblk_4-error-recovery-method-introduction-12_8_8_20042453.html
http://blog.itpub.net/29863023/viewspace-2132815/
6 感谢
各位老铁,如果觉得我的视频内容有用,能帮助到你,请帮忙一键三连,顺手转发给更多的朋友。
访问我的个人站点,查看本视频中提到的所有文档和资料素材: http://oracleonlinux.cn/
感谢大家的收看,我们下一期视频节目再见。
最后,欢迎大家关注我的个人微信公众号。