在上一篇文章,索引扫描路径之1:Index Unique Scan 中,详细描述了Oracle的CBO优化器会在何种情形下选择通过Index Unique Scan的方式来访问数据。
本篇描述CBO优化器会在什么场景下选择Index Range Scan的路径来访问数据?
Index Range Scan通常见于通过索引去查找具有高选择性的数据。默认情况下,Oracle是按照被索引字段升序排序来存放索引记录的,如果被索引字段有重复值,则按照相应的ROWID做升序排序来存放。
较为常见的Index Range Scan的WHERE条件如下:
Col1=:b1
Col1>:b1
Col1>=:b1
Col1<:b1
Col1<=:b1
或者是通过AND连接的满足上述可构成前导列的条件。再或者WHERE条件中有使用BETWEEN…AND条件。
同样,给出验证与说明:
系统版本、数据库版本和平台,以及测试表同与之前的环境。即选择Linux X86_64平台上的一套11.2.0.1.0库,使用HR这个schema下的departments表。
1 唯一索引,CBO选择Index Range Scan的场景:
SQL> set autotrace trace
SQL> select * from departments where department_id>260;
Execution Plan
----------------------------------------------------------
Plan hash value: 3346631158
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 20 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_ID_PK | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPARTMENT_ID">260)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
743 bytes sent via SQL*Net to client
492 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
从上,即使是从唯一索引中获取一条数据[满足department_id>260条件的记录,确实只有1条],优化器也选择了走INDEX RANGE SCAN,因为上述SQL并不满足Index Unique Scan的条件。恰恰满足了INDEX RANGE SCAN 的条件。
2 接下来,一个典型的使用INDEX RANGE SCAN 的场景:
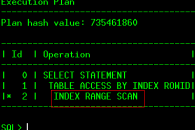
SQL> select * from departments where location_id=1700;
21 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 735461860
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 21 | 420 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 21 | 420 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 21 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LOCATION_ID"=1700)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
6 consistent gets
1 physical reads
0 redo size
1468 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
21 rows processed
SQL>
或者:
SQL> select * from departments where location_id<=1700;
23 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 735461860
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 24 | 480 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 24 | 480 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 24 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LOCATION_ID"<=1700)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
1502 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
23 rows processed
SQL>
再或者:
SQL> select * from departments where location_id>=1700;
25 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 735461860
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 25 | 500 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 25 | 500 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 25 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LOCATION_ID">=1700)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
1561 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
25 rows processed
SQL>
可以看到,不管是location_id>=1700还是location_id=1700或者是location_id<=1700条件,CBO都选择了location_id字段上的索引DEPT_LOCATION_IX通过INDEX RANGE SCAN 的方式去获取数据。
3 接下来,BETWEEN…AND的场景:
SQL> select department_id,location_id,rowid from departments where location_id between 1500 and 2600;
25 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 735461860
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 26 | 494 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 26 | 494 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 26 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LOCATION_ID">=1500 AND "LOCATION_ID"<=2600)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
1556 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
25 rows processed
SQL>
那么,如果是通过department_id字段来做BETWEEN…AND条件测试呢?即测试在一个唯一性索引上使用BETWEEN…AND条件的情形。
SQL> select department_id,location_id,rowid from departments where department_id between 120 and 130;
Execution Plan
----------------------------------------------------------
Plan hash value: 3346631158
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 57 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 3 | 57 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | DEPT_ID_PK | 3 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPARTMENT_ID">=120 AND "DEPARTMENT_ID"<=130)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
748 bytes sent via SQL*Net to client
492 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
SQL>
测试结果发现,即使是唯一索引,CBO依然会选择INDEX RANGE SCAN。
反之,如果条件换做是department_id between 120 and 120的话,很明显,聪明的CBO这次肯定会选择Index Unique Scan。
SQL> select department_id,location_id,rowid from departments where department_id between 120 and 120;
Execution Plan
----------------------------------------------------------
Plan hash value: 4024094692
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 19 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 19 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPARTMENT_ID"=120)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
673 bytes sent via SQL*Net to client
492 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
4 最后,看一个关于INDEX RANGE SCAN DESCENDING的场景:
CBO选择INDEX RANGE SCAN DESCENDING的方式来获取数据,适用于 ORDER BY column_name DESC的场景。在默认情况下,索引是按照索引关键字升序来存放数据的。
按照常理来讲,如果有ORDER BY column_name DESC的条件,那么
① 需要先从索引中读取数据;
② 再按照条件中column_name字段做降序排序。
而选择INDEX RANGE SCAN DESCENDING,则是直接在索引上按照索引关键字降序查找数据,这样正是为了避免先按照索引来查找数据,然后再做一次降序排序的操作。
SQL> set autotrace on
SQL> select department_id,location_id,rowid from departments where location_id between 1500 and 2600 order by location_id desc;
DEPARTMENT_ID LOCATION_ID ROWID
------------- ----------- ------------------
80 2500 AAAz+PABRAAAACbAAH
40 2400 AAAz+PABRAAAACbAAD
20 1800 AAAz+PABRAAAACbAAB
270 1700 AAAz+PABRAAAACbAAa
260 1700 AAAz+PABRAAAACbAAZ
250 1700 AAAz+PABRAAAACbAAY
240 1700 AAAz+PABRAAAACbAAX
230 1700 AAAz+PABRAAAACbAAW
220 1700 AAAz+PABRAAAACbAAV
210 1700 AAAz+PABRAAAACbAAU
200 1700 AAAz+PABRAAAACbAAT
DEPARTMENT_ID LOCATION_ID ROWID
------------- ----------- ------------------
190 1700 AAAz+PABRAAAACbAAS
180 1700 AAAz+PABRAAAACbAAR
170 1700 AAAz+PABRAAAACbAAQ
160 1700 AAAz+PABRAAAACbAAP
150 1700 AAAz+PABRAAAACbAAO
140 1700 AAAz+PABRAAAACbAAN
130 1700 AAAz+PABRAAAACbAAM
120 1700 AAAz+PABRAAAACbAAL
110 1700 AAAz+PABRAAAACbAAK
100 1700 AAAz+PABRAAAACbAAJ
90 1700 AAAz+PABRAAAACbAAI
DEPARTMENT_ID LOCATION_ID ROWID
------------- ----------- ------------------
30 1700 AAAz+PABRAAAACbAAC
10 1700 AAAz+PABRAAAACbAAA
50 1500 AAAz+PABRAAAACbAAE
25 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2689299823
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 26 | 494 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | DEPARTMENTS | 26 | 494 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| DEPT_LOCATION_IX | 26 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LOCATION_ID">=1500 AND "LOCATION_ID"<=2600)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
1575 bytes sent via SQL*Net to client
534 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
25 rows processed
SQL>
从上可以看到,对于LOCATION_ID=1700的记录,则正是按照ROWID做的降序排序操作。